CrateDB基于NoSQL的架构,但是有标准SQL的特性。它是一个无共享的分布式的数据库,支持文档和动态模式的关系。它安装和使用起来非常简单,有着自动分片,自动分区,自动复制的功能。实现了实时搜索和聚合,而且有通过部署CrateDB来水平扩展。它提供写后一致性,平衡内存磁盘的使用量而且是微服务(例如Docker)的理想选择。CrateDB是一个开源的数据库而且在Apache 2.0许可之下。
索引: 默认情况下,CrateDB对所有字段进行索引,将数据存储在列中,这些字段针对过滤和聚合做了一些优化。表上不需要加锁以便添加新列甚至嵌套对象。
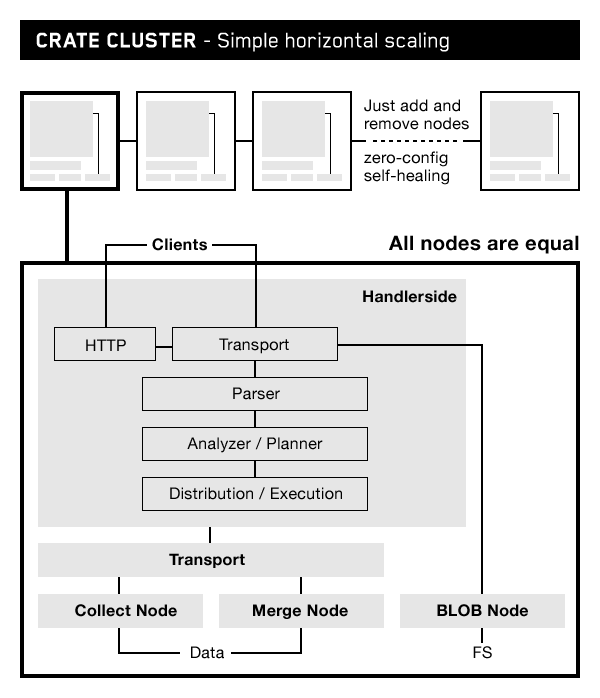
无主节点:一个CrateDB 集群是一个无主的,有一组对等节点。可以部署在任意地方:在笔记本上,部署在私有云和共有云上。你可以最大化性价比在廉价的通用的服务器上部署,而且任然可以获取较快较高的性能。
为微服务制作:使用官方的Docker容器允许你快速而且简单地部署CrateDB节点。CrateDB可以在GCE(谷歌的云)上一键部署,而且AWS上有官方的亚马逊的镜像。
更多的架构和技术细节,阅读此技术概览。
可扩展的
CrateDB 已经部署在生产环境中,具有以下规模:
- 每天有数十亿的插入和更新(同时提供面向用户的实时查询)
- 100+的节点(AWS和内部部署)
- 100多TB的数据
- 每秒150多万条的插入(每个节点每秒4万条)
- 10万用户的并发下每秒支持的请求更多(实践的例子:每秒330,000的插入(每个1KB)下,同时面向用户服务,全文查询时延小于400毫秒,运行在8个商用服务器(每个$2000),有64G内存,使用SSD硬盘。
- 云服务提供商的多个可用区域